6 Joining Data with dplyr
https://learn.datacamp.com/courses/joining-data-with-dplyr
Main functions and concepts covered in this BP chapter:
inner_join()left_join()right_join()full_join()semi_join()anti_join()
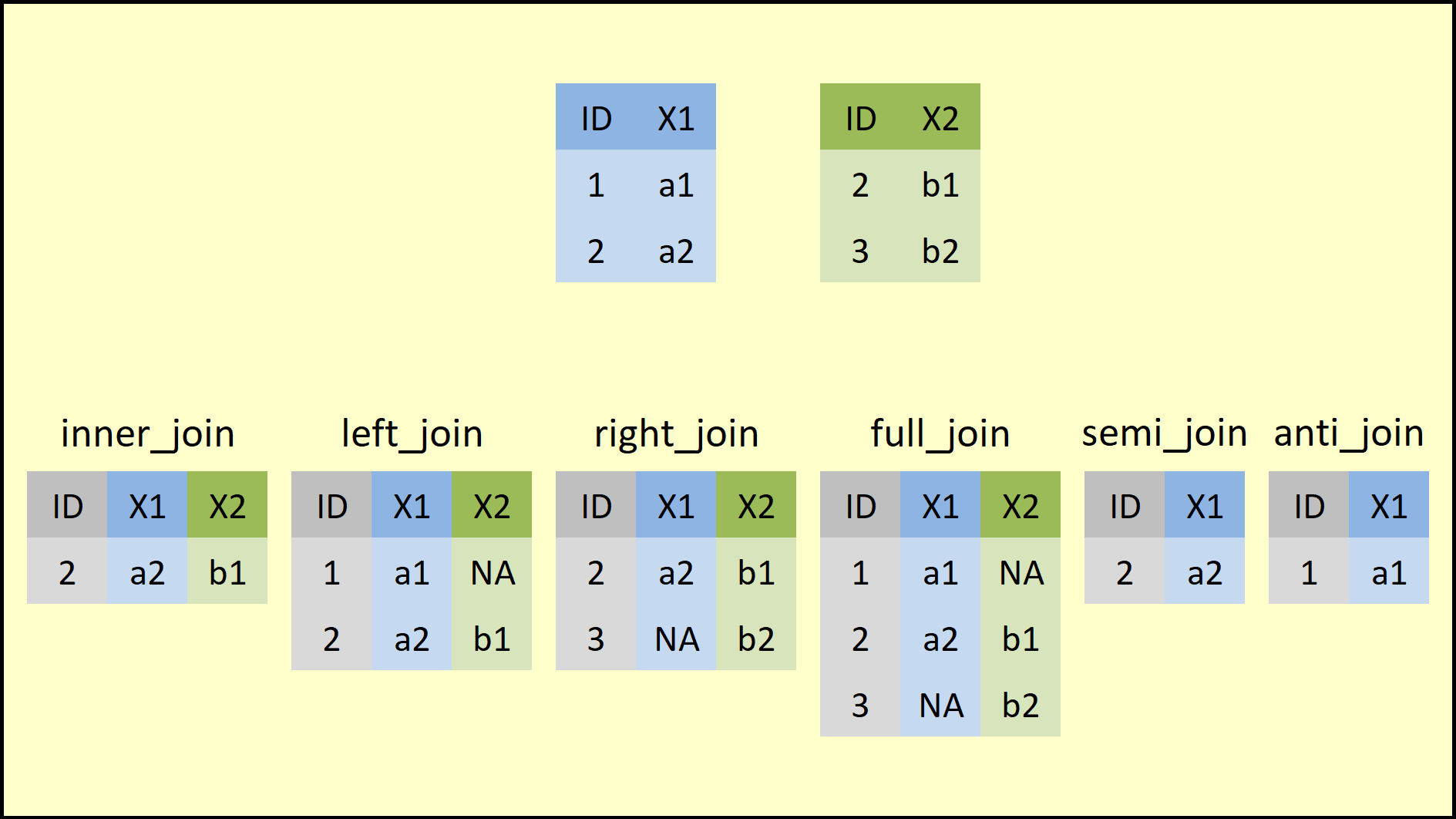
source: https://statisticsglobe.com/r-dplyr-join-inner-left-right-full-semi-anti
Packages used in this chapter:
## Load all packages used in this chapter
library(tidyverse) #includes dplyr, ggplot2, and other common packages## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
## ✔ ggplot2 3.4.0 ✔ purrr 0.3.5
## ✔ tibble 3.1.8 ✔ dplyr 1.0.10
## ✔ tidyr 1.2.1 ✔ stringr 1.5.0
## ✔ readr 2.1.3 ✔ forcats 0.5.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()library(lubridate)## Loading required package: timechange
##
## Attaching package: 'lubridate'
##
## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, unionDatasets used in this chapter:
## Load datasets used in this chapter
parts <- read_rds("data/parts.rds")
part_categories <- read_rds("data/part_categories.rds")
inventory_parts <- read_rds("data/inventory_parts.rds")
inventories <- read_rds("data/inventories.rds")
sets <- read_rds("data/sets.rds")
colors <- read_rds("data/colors.rds")
themes <- read_rds("data/themes.rds")
questions <- read_rds("data/questions.rds")
question_tags <- read_rds("data/question_tags.rds")
tags <- read_rds("data/tags.rds")
answers <- read_rds("data/answers.rds")Tip: one of the common mistakes that leads to people getting stuck in the by argument, mixing up by=c("var1"="var2") versus by=c("var1", "var2")
Note: In some exercises they have you replace NAs with 0. This is correct in these particular cases, but this is not always correct. It’s only correct if NA actually represents 0 (which it does in these exercises). (For example, if we had a dataset on people that asked how many cigarettes smoked per day and it was NA for some observations, we couldn’t assume NA means 0 because it might actually be 40 but they just didn’t answer that question.)
6.1 Joining Tables
6.1.1 Joining 2 Tables
The inner_join is the key to bring tables together. To use it, you need to provide the two tables that must be joined and the columns on which they should be joined.
The by argument expects a named vector containing the columns that will join each table: c("first_table_column" = "second_table_column").
# Add the correct verb, table, and joining column (part_categories is the name of the second table, part_cat_id is a part of the parts table and id is part of the second table)
parts %>%
inner_join(part_categories, by = c("part_cat_id" = "id"))## # A tibble: 17,501 × 4
## part_num name.x part_…¹ name.y
## <chr> <chr> <dbl> <chr>
## 1 0901 Baseplate 16 x 30 with Set 080 Yellow House Print 1 Basep…
## 2 0902 Baseplate 16 x 24 with Set 080 Small White House P… 1 Basep…
## 3 0903 Baseplate 16 x 24 with Set 080 Red House Print 1 Basep…
## 4 0904 Baseplate 16 x 24 with Set 080 Large White House P… 1 Basep…
## 5 1 Homemaker Bookcase 2 x 4 x 4 7 Conta…
## 6 10016414 Sticker Sheet #1 for 41055-1 58 Stick…
## 7 10026stk01 Sticker for Set 10026 - (44942/4184185) 58 Stick…
## 8 10039 Pullback Motor 8 x 4 x 2/3 44 Mecha…
## 9 10048 Minifig Hair Tousled 65 Minif…
## 10 10049 Minifig Shield Broad with Spiked Bottom and Cutout… 27 Minif…
## # … with 17,491 more rows, and abbreviated variable name ¹part_cat_id# Use the suffix argument to replace .x and .y suffixes (if you don't the first column will be name.x and the second is name.y)
parts %>%
inner_join(part_categories, by = c("part_cat_id" = "id"), suffix = c("_part", "_category"))## # A tibble: 17,501 × 4
## part_num name_part part_…¹ name_…²
## <chr> <chr> <dbl> <chr>
## 1 0901 Baseplate 16 x 30 with Set 080 Yellow House Print 1 Basepl…
## 2 0902 Baseplate 16 x 24 with Set 080 Small White House … 1 Basepl…
## 3 0903 Baseplate 16 x 24 with Set 080 Red House Print 1 Basepl…
## 4 0904 Baseplate 16 x 24 with Set 080 Large White House … 1 Basepl…
## 5 1 Homemaker Bookcase 2 x 4 x 4 7 Contai…
## 6 10016414 Sticker Sheet #1 for 41055-1 58 Sticke…
## 7 10026stk01 Sticker for Set 10026 - (44942/4184185) 58 Sticke…
## 8 10039 Pullback Motor 8 x 4 x 2/3 44 Mechan…
## 9 10048 Minifig Hair Tousled 65 Minifi…
## 10 10049 Minifig Shield Broad with Spiked Bottom and Cutou… 27 Minifi…
## # … with 17,491 more rows, and abbreviated variable names ¹part_cat_id,
## # ²name_categoryJoining two tables together with one-to-many relationship increases the amount of rows in the table.
# Combine the parts and inventory_parts tables (when the columns from the first and second table have the same name, you can just write "by = 'columnname'")
parts %>%
inner_join(inventory_parts, by = "part_num")## # A tibble: 258,958 × 6
## part_num name part_…¹ inven…² color…³ quant…⁴
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 0901 Baseplate 16 x 30 with Set 080 Yell… 1 1973 2 1
## 2 0902 Baseplate 16 x 24 with Set 080 Smal… 1 1973 2 1
## 3 0903 Baseplate 16 x 24 with Set 080 Red … 1 1973 2 1
## 4 0904 Baseplate 16 x 24 with Set 080 Larg… 1 1973 2 1
## 5 1 Homemaker Bookcase 2 x 4 x 4 7 508 15 1
## 6 1 Homemaker Bookcase 2 x 4 x 4 7 1158 15 2
## 7 1 Homemaker Bookcase 2 x 4 x 4 7 6590 15 2
## 8 1 Homemaker Bookcase 2 x 4 x 4 7 9679 15 2
## 9 1 Homemaker Bookcase 2 x 4 x 4 7 12256 1 2
## 10 1 Homemaker Bookcase 2 x 4 x 4 7 13356 15 1
## # … with 258,948 more rows, and abbreviated variable names ¹part_cat_id,
## # ²inventory_id, ³color_id, ⁴quantity#You can reverse the code and switch parts with inventory_parts and get the same table.6.1.2 Joining 3 or More Tables
You can string together multiple joins with inner_join and the pipe (%>%).
sets %>%
# Add inventories using an inner join
inner_join(inventories, by = "set_num" ) %>%
# Add inventory_parts using an inner join
inner_join(inventory_parts, c("id" = "inventory_id"))## # A tibble: 258,958 × 9
## set_num name year theme…¹ id version part_…² color…³ quant…⁴
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 700.3-1 Medium Gift Set … 1949 365 24197 1 bdoor01 2 2
## 2 700.3-1 Medium Gift Set … 1949 365 24197 1 bdoor01 15 1
## 3 700.3-1 Medium Gift Set … 1949 365 24197 1 bdoor01 4 1
## 4 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot02 15 6
## 5 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot02 2 6
## 6 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot02 4 6
## 7 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot02 1 6
## 8 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot02 14 6
## 9 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot0… 15 6
## 10 700.3-1 Medium Gift Set … 1949 365 24197 1 bslot0… 2 6
## # … with 258,948 more rows, and abbreviated variable names ¹theme_id,
## # ²part_num, ³color_id, ⁴quantity# Here, we joined inventories to sets, and then inventory parts to inventories, which was already joined with sets.# Add an inner join for the colors table and add a suffix, then count the number of colors so the most prominent colors appear first
sets %>%
inner_join(inventories, by = "set_num") %>%
inner_join(inventory_parts, by = c("id" = "inventory_id")) %>%
inner_join(colors, c("color_id" = "id"), suffix = c("_set", "_color")) %>%
count(name_color, sort = TRUE)## # A tibble: 134 × 2
## name_color n
## <chr> <int>
## 1 Black 48068
## 2 White 30105
## 3 Light Bluish Gray 26024
## 4 Red 21602
## 5 Dark Bluish Gray 19948
## 6 Yellow 17088
## 7 Blue 12980
## 8 Light Gray 8632
## 9 Reddish Brown 6960
## 10 Tan 6664
## # … with 124 more rows6.2 Left and Right Joins
We need this to work with what they give us. You can run it at the start of this section.
inventory_parts_joined <- sets %>%
inner_join(inventories, by = "set_num") %>%
inner_join(inventory_parts, by = c("id" = "inventory_id")) %>%
inner_join(colors, by = c("color_id" = "id"), suffix = c("_set", "_color")) %>%
select(set_num, part_num, color_id, quantity)
millennium_falcon <- inventory_parts_joined %>%
filter(set_num == "7965-1")
star_destroyer <- inventory_parts_joined %>%
filter(set_num == "75190-1")6.2.1 Left Join
An inner join keeps only observations that appear in both tables. But if you want to keep all the observations in one of the tables, you can use a different dplyr verb: left join().
# Combine the star_destroyer and millennium_falcon tables
millennium_falcon %>%
left_join(star_destroyer, by = c("part_num", "color_id"), suffix = c("_falcon", "_star_destroyer"))## # A tibble: 263 × 6
## set_num_falcon part_num color_id quantity_falcon set_num_star_destr…¹ quant…²
## <chr> <chr> <dbl> <dbl> <chr> <dbl>
## 1 7965-1 12825 72 3 <NA> NA
## 2 7965-1 2412b 72 20 75190-1 11
## 3 7965-1 2412b 320 2 <NA> NA
## 4 7965-1 2419 71 1 <NA> NA
## 5 7965-1 2420 0 4 75190-1 1
## 6 7965-1 2420 71 1 <NA> NA
## 7 7965-1 2420 71 7 <NA> NA
## 8 7965-1 2431 72 2 <NA> NA
## 9 7965-1 2431 0 1 75190-1 3
## 10 7965-1 2431 19 2 <NA> NA
## # … with 253 more rows, and abbreviated variable names ¹set_num_star_destroyer,
## # ²quantity_star_destroyer# Aggregate Millennium Falcon for the total quantity in each part
millennium_falcon_colors <- millennium_falcon %>%
group_by(color_id) %>%
summarize(total_quantity = sum(quantity))
# Aggregate Star Destroyer for the total quantity in each part
star_destroyer_colors <- star_destroyer %>%
group_by(color_id) %>%
summarize(total_quantity = sum(quantity))
# Left join the Millennium Falcon colors to the Star Destroyer colors
millennium_falcon_colors %>%
left_join(star_destroyer_colors, by = "color_id", suffix = c("_falcon", "_star_destroyer"))## # A tibble: 21 × 3
## color_id total_quantity_falcon total_quantity_star_destroyer
## <dbl> <dbl> <dbl>
## 1 0 201 336
## 2 1 15 23
## 3 4 17 53
## 4 14 3 4
## 5 15 15 17
## 6 19 95 12
## 7 28 3 16
## 8 33 5 NA
## 9 36 1 14
## 10 41 6 15
## # … with 11 more rowsLeft joins are really great for testing your assumptions about a data set and ensuring your data has integrity.
For example, the inventories table has a version column, for when a LEGO kit gets some kind of change or upgrade. It would be fair to assume that all sets (which joins well with inventories) would have at least a version 1. But let’s test this assumption out.
inventory_version_1 <- inventories %>%
filter(version == 1)
# Join versions to sets
sets %>%
left_join(inventory_version_1, by = "set_num") %>%
# Filter for where version is na
filter(is.na(version))## # A tibble: 1 × 6
## set_num name year theme_id id version
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 40198-1 Ludo game 2018 598 NA NA6.2.2 Right Join
Just as left joins keep all the observations from the first (or “left”) table, whether or not they appear in the second (or “right”) table, a right join keeps all the observations in the second (or “right”) table, whether or not they appear in the first table.
In the code below, we find an instance where a part category is present in one table, but missing from the other table. It’s important to understand which entries would be impacted by replace_na(), so that we know which entries we would be omitting by using that function.
parts %>%
count(part_cat_id) %>%
right_join(part_categories, by = c("part_cat_id" = "id")) %>%
# Filter for NA
filter(is.na(n))## # A tibble: 1 × 3
## part_cat_id n name
## <dbl> <int> <chr>
## 1 66 NA Modulex# Use replace_na to replace missing values in the n column
parts %>%
replace_na(list(n = 0))## # A tibble: 17,501 × 3
## part_num name part_c…¹
## <chr> <chr> <dbl>
## 1 0901 Baseplate 16 x 30 with Set 080 Yellow House Print 1
## 2 0902 Baseplate 16 x 24 with Set 080 Small White House Print 1
## 3 0903 Baseplate 16 x 24 with Set 080 Red House Print 1
## 4 0904 Baseplate 16 x 24 with Set 080 Large White House Print 1
## 5 1 Homemaker Bookcase 2 x 4 x 4 7
## 6 10016414 Sticker Sheet #1 for 41055-1 58
## 7 10026stk01 Sticker for Set 10026 - (44942/4184185) 58
## 8 10039 Pullback Motor 8 x 4 x 2/3 44
## 9 10048 Minifig Hair Tousled 65
## 10 10049 Minifig Shield Broad with Spiked Bottom and Cutout Corner 27
## # … with 17,491 more rows, and abbreviated variable name ¹part_cat_id6.2.3 Theme Hierarchy
Tables can be joined to themselves.
In the themes table, which is available for you to inspect in the console, you’ll notice there is both an id column and a parent_id column. Keeping that in mind, you can join the themes table to itself to determine the parent-child relationships that exist for different themes.
In this exercise, you’ll try a similar approach of joining themes to their own children, which is similar but reversed. Let’s try this out to discover what children the theme “Harry Potter” has.
themes %>%
# Inner join the themes table
inner_join(themes, by = c("id" = "parent_id"), suffix = c("_parent", "_child")) %>%
# Filter for the "Harry Potter" parent name
filter(name_parent == "Harry Potter")## # A tibble: 6 × 5
## id name_parent parent_id id_child name_child
## <dbl> <chr> <dbl> <dbl> <chr>
## 1 246 Harry Potter NA 247 Chamber of Secrets
## 2 246 Harry Potter NA 248 Goblet of Fire
## 3 246 Harry Potter NA 249 Order of the Phoenix
## 4 246 Harry Potter NA 250 Prisoner of Azkaban
## 5 246 Harry Potter NA 251 Sorcerer's Stone
## 6 246 Harry Potter NA 667 Fantastic BeastsHere, we can inner join themes to a filtered version of itself again to establish a connection between our last join’s children and their children.
# Join themes to itself again to find the grandchild relationships
themes %>%
inner_join(themes, by = c("id" = "parent_id"), suffix = c("_parent", "_child")) %>%
inner_join(themes, by = c("id_child" = "parent_id"), suffix = c("_parent", "_grandchild"))## # A tibble: 158 × 7
## id_parent name_parent parent_id id_child name_child id_grandchild name
## <dbl> <chr> <dbl> <dbl> <chr> <dbl> <chr>
## 1 1 Technic NA 5 Model 6 Airport
## 2 1 Technic NA 5 Model 7 Constructi…
## 3 1 Technic NA 5 Model 8 Farm
## 4 1 Technic NA 5 Model 9 Fire
## 5 1 Technic NA 5 Model 10 Harbor
## 6 1 Technic NA 5 Model 11 Off-Road
## 7 1 Technic NA 5 Model 12 Race
## 8 1 Technic NA 5 Model 13 Riding Cyc…
## 9 1 Technic NA 5 Model 14 Robot
## 10 1 Technic NA 5 Model 15 Traffic
## # … with 148 more rowsSome themes might not have any children at all, which means they won’t be included in the inner join. As you’ve learned in this chapter, you can identify those with a left_join and a filter().
themes %>%
# Left join the themes table to its own children
left_join(themes, by = c("id" = "parent_id"), suffix = c("_parent", "_child")) %>%
# Filter for themes that have no child themes
filter(is.na(name_child))## # A tibble: 586 × 5
## id name_parent parent_id id_child name_child
## <dbl> <chr> <dbl> <dbl> <chr>
## 1 2 Arctic Technic 1 NA <NA>
## 2 3 Competition 1 NA <NA>
## 3 4 Expert Builder 1 NA <NA>
## 4 6 Airport 5 NA <NA>
## 5 7 Construction 5 NA <NA>
## 6 8 Farm 5 NA <NA>
## 7 9 Fire 5 NA <NA>
## 8 10 Harbor 5 NA <NA>
## 9 11 Off-Road 5 NA <NA>
## 10 12 Race 5 NA <NA>
## # … with 576 more rows6.3 Full, Semi, and Anti Joins
6.3.1 Full Join
A left join would keep all the observations in batmobile, a right join would keep all the observations in batwing. A full join keeps all the observations in either. All the other arguments, like by and suffix, are the same.
# Start with inventory_parts_joined table
inventory_parts_joined %>%
# Combine with the sets table
inner_join(sets, by = "set_num") %>%
# Combine with the themes table
inner_join(themes, by = c("theme_id" = "id"), suffix = c("_set", "_theme"))## # A tibble: 258,958 × 9
## set_num part_num color_id quantity name_set year theme…¹ name_…² paren…³
## <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <chr> <dbl>
## 1 700.3-1 bdoor01 2 2 Medium Gift… 1949 365 System NA
## 2 700.3-1 bdoor01 15 1 Medium Gift… 1949 365 System NA
## 3 700.3-1 bdoor01 4 1 Medium Gift… 1949 365 System NA
## 4 700.3-1 bslot02 15 6 Medium Gift… 1949 365 System NA
## 5 700.3-1 bslot02 2 6 Medium Gift… 1949 365 System NA
## 6 700.3-1 bslot02 4 6 Medium Gift… 1949 365 System NA
## 7 700.3-1 bslot02 1 6 Medium Gift… 1949 365 System NA
## 8 700.3-1 bslot02 14 6 Medium Gift… 1949 365 System NA
## 9 700.3-1 bslot02a 15 6 Medium Gift… 1949 365 System NA
## 10 700.3-1 bslot02a 2 6 Medium Gift… 1949 365 System NA
## # … with 258,948 more rows, and abbreviated variable names ¹theme_id,
## # ²name_theme, ³parent_idinventory_sets_themes <- inventory_parts_joined %>%
inner_join(sets, by = "set_num") %>%
inner_join(themes, by = c("theme_id" = "id"), suffix = c("_set", "_theme"))
batman <- inventory_sets_themes %>%
filter(name_theme == "Batman")
star_wars <- inventory_sets_themes %>%
filter(name_theme == "Star Wars")
# Count the part number and color id, weight by quantity
batman %>%
count(part_num, color_id, wt = quantity)## # A tibble: 2,071 × 3
## part_num color_id n
## <chr> <dbl> <dbl>
## 1 10113 0 11
## 2 10113 272 1
## 3 10113 320 1
## 4 10183 57 1
## 5 10190 0 2
## 6 10201 0 1
## 7 10201 4 3
## 8 10201 14 1
## 9 10201 15 6
## 10 10201 71 4
## # … with 2,061 more rowsstar_wars %>%
count(part_num, color_id, wt = quantity)## # A tibble: 2,413 × 3
## part_num color_id n
## <chr> <dbl> <dbl>
## 1 10169 4 1
## 2 10197 0 2
## 3 10197 72 3
## 4 10201 0 21
## 5 10201 71 5
## 6 10247 0 9
## 7 10247 71 16
## 8 10247 72 12
## 9 10884 28 1
## 10 10928 72 6
## # … with 2,403 more rowsbatman_parts <- batman %>%
count(part_num, color_id, wt = quantity)
star_wars_parts <- star_wars %>%
count(part_num, color_id, wt = quantity)
parts_joined <- batman_parts %>%
# Combine the star_wars_parts table
full_join(star_wars_parts, by = c("part_num", "color_id"), suffix = c("_batman", "_star_wars")) %>%
# Replace NAs with 0s in the n_batman and n_star_wars columns
replace_na(list(n_batman = 0, n_star_wars = 0))
parts_joined## # A tibble: 3,628 × 4
## part_num color_id n_batman n_star_wars
## <chr> <dbl> <dbl> <dbl>
## 1 10113 0 11 0
## 2 10113 272 1 0
## 3 10113 320 1 0
## 4 10183 57 1 0
## 5 10190 0 2 0
## 6 10201 0 1 21
## 7 10201 4 3 0
## 8 10201 14 1 0
## 9 10201 15 6 0
## 10 10201 71 4 5
## # … with 3,618 more rowsparts_joined %>%
# Sort the number of star wars pieces in descending order
arrange(desc(n_star_wars)) %>%
# Join the colors table to the parts_joined table
inner_join(colors, by = c("color_id" = "id")) %>%
# Join the parts table to the previous join
inner_join(parts, by = "part_num", suffix = c("_color", "_part"))## # A tibble: 3,628 × 8
## part_num color_id n_batman n_star_wars name_color rgb name_…¹ part_…²
## <chr> <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 2780 0 104 392 Black #051… Techni… 53
## 2 32062 0 1 141 Black #051… Techni… 46
## 3 4274 1 56 118 Blue #005… Techni… 53
## 4 6141 36 11 117 Trans-Red #C91… Plate … 21
## 5 3023 71 10 106 Light Bluish Gr… #A0A… Plate … 14
## 6 6558 1 30 106 Blue #005… Techni… 53
## 7 43093 1 44 99 Blue #005… Techni… 53
## 8 3022 72 14 95 Dark Bluish Gray #6C6… Plate … 14
## 9 2357 19 0 84 Tan #E4C… Brick … 11
## 10 6141 179 90 81 Flat Silver #898… Plate … 21
## # … with 3,618 more rows, and abbreviated variable names ¹name_part,
## # ²part_cat_id6.3.2 Filtering Join
A filtering join keeps or removes observations from the first table, but it doesn’t add new variables. The two filtering verbs you’ll be learning are semi join and anti join.
A semi join asks the question: what observations in X are also in Y?
An anti join asks the question: what observations in X are not in Y?
batmobile <- inventory_parts_joined %>%
filter(set_num == "7784-1") %>%
select(-set_num)
batwing <- inventory_parts_joined %>%
filter(set_num == "70916-1") %>%
select(-set_num)
# Filter the batwing set for parts that are also in the batmobile set
batwing %>%
semi_join(batmobile, by = "part_num")## # A tibble: 126 × 3
## part_num color_id quantity
## <chr> <dbl> <dbl>
## 1 2412b 72 6
## 2 2412b 71 10
## 3 2412b 70 2
## 4 2412b 4 2
## 5 2412b 0 4
## 6 2420 71 2
## 7 2780 0 17
## 8 3001 15 2
## 9 3001 0 4
## 10 3001 1 4
## # … with 116 more rows# Filter the batwing set for parts that aren't in the batmobile set
batwing %>%
anti_join(batmobile, by = "part_num")## # A tibble: 183 × 3
## part_num color_id quantity
## <chr> <dbl> <dbl>
## 1 10113 0 1
## 2 10247 72 12
## 3 11090 72 2
## 4 11153 0 10
## 5 11211 71 2
## 6 11212 71 2
## 7 11477 72 4
## 8 11477 0 18
## 9 13349 72 2
## 10 13731 0 4
## # … with 173 more rows# Use inventory_parts to find colors included in at least one set
colors %>%
semi_join(inventory_parts, by = c("id" = "color_id"))## # A tibble: 134 × 3
## id name rgb
## <dbl> <chr> <chr>
## 1 -1 [Unknown] #0033B2
## 2 0 Black #05131D
## 3 1 Blue #0055BF
## 4 2 Green #237841
## 5 3 Dark Turquoise #008F9B
## 6 4 Red #C91A09
## 7 5 Dark Pink #C870A0
## 8 6 Brown #583927
## 9 7 Light Gray #9BA19D
## 10 8 Dark Gray #6D6E5C
## # … with 124 more rows# Use filter() to extract version 1
version_1_inventories <- inventories %>%
filter(version == 1)
# Use anti_join() to find which set is missing a version 1
sets %>%
anti_join(version_1_inventories, by = "set_num")## # A tibble: 1 × 4
## set_num name year theme_id
## <chr> <chr> <dbl> <dbl>
## 1 40198-1 Ludo game 2018 598inventory_parts_themes <- inventories %>%
inner_join(inventory_parts, by = c("id" = "inventory_id")) %>%
arrange(desc(quantity)) %>%
select(-id, -version) %>%
inner_join(sets, by = "set_num") %>%
inner_join(themes, by = c("theme_id" = "id"), suffix = c("_set", "_theme"))
batman_colors <- inventory_parts_themes %>%
# Filter the inventory_parts_themes table for the Batman theme
filter(name_theme == "Batman") %>%
group_by(color_id) %>%
summarize(total = sum(quantity)) %>%
# Add a fraction column of the total divided by the sum of the total
mutate(fraction = total / sum(total))
# Filter and aggregate the Star Wars set data; add a fraction column
star_wars_colors <- inventory_parts_themes %>%
filter(name_theme == "Star Wars") %>%
group_by(color_id) %>%
summarize(total = sum(quantity)) %>%
# Add a fraction column of the total divided by the sum of the total
mutate(fraction = total / sum(total))colors_joined <- batman_colors %>%
# Join the Batman and Star Wars colors
full_join(star_wars_colors, by = "color_id", suffix = c("_batman", "_star_wars")) %>%
# Replace NAs in the total_batman and total_star_wars columns
replace_na(list(total_batman = 0, total_star_wars = 0)) %>%
inner_join(colors, by = c("color_id" = "id"))%>%
# Create the difference and total columns
mutate(difference = fraction_batman - fraction_star_wars,
total = total_batman + total_star_wars) %>%
# Filter for totals greater than 200
filter(total >= 200)
colors_joined## # A tibble: 16 × 9
## color_id total_batman fraction_b…¹ total…² fract…³ name rgb differ…⁴ total
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl>
## 1 0 2807 0.296 3258 0.207 Black #051… 8.89e-2 6065
## 2 1 243 0.0256 410 0.0261 Blue #005… -4.39e-4 653
## 3 4 529 0.0558 434 0.0276 Red #C91… 2.82e-2 963
## 4 14 426 0.0449 207 0.0132 Yell… #F2C… 3.18e-2 633
## 5 15 404 0.0426 1771 0.113 White #FFF… -7.00e-2 2175
## 6 19 142 0.0150 1012 0.0644 Tan #E4C… -4.94e-2 1154
## 7 28 98 0.0103 183 0.0116 Dark… #958… -1.30e-3 281
## 8 36 86 0.00907 246 0.0156 Tran… #C91… -6.57e-3 332
## 9 46 200 0.0211 39 0.00248 Tran… #F5C… 1.86e-2 239
## 10 70 297 0.0313 373 0.0237 Redd… #582… 7.61e-3 670
## 11 71 1148 0.121 3264 0.208 Ligh… #A0A… -8.65e-2 4412
## 12 72 1453 0.153 2433 0.155 Dark… #6C6… -1.44e-3 3886
## 13 84 278 0.0293 31 0.00197 Medi… #CC7… 2.74e-2 309
## 14 179 154 0.0162 232 0.0148 Flat… #898… 1.49e-3 386
## 15 378 22 0.00232 430 0.0273 Sand… #A0B… -2.50e-2 452
## 16 7 0 NA 209 0.0133 Ligh… #9BA… NA 209
## # … with abbreviated variable names ¹fraction_batman, ²total_star_wars,
## # ³fraction_star_wars, ⁴difference# For some reason I got one color with a difference of NA...
# you don't have to drop it, but you avoid an error if you do.
# Even better is figuring out how to avoid the NA in the first place...
# You also need to arrange the data by difference (that's how it is in the graph)
colors_joined <- colors_joined %>% arrange(difference) %>% filter(!is.na(difference))
# These two lines get the color names to display in order of difference.
# There are other ways (they mention the "forcats" package in the video),
# but like many things, I googled it and I found a solution tat I adapted to this and it worked
colors_joined$name <- as.character(colors_joined$name)
colors_joined$name <- factor(colors_joined$name, levels=colors_joined$name)
# Create the color palette itself, which is just the colors and their names
color_palette_df <- colors %>%
semi_join(colors_joined, by = c("id" = "color_id")) %>%
select(-id)
color_palette <- color_palette_df$rgb
names(color_palette) <- color_palette_df$name# Create a bar plot using colors_joined and the name and difference columns
ggplot(colors_joined, aes(name, difference, fill = name)) +
geom_col() +
coord_flip() +
scale_fill_manual(values = color_palette, guide = "none") +
labs(y = "Difference: Batman - Star Wars")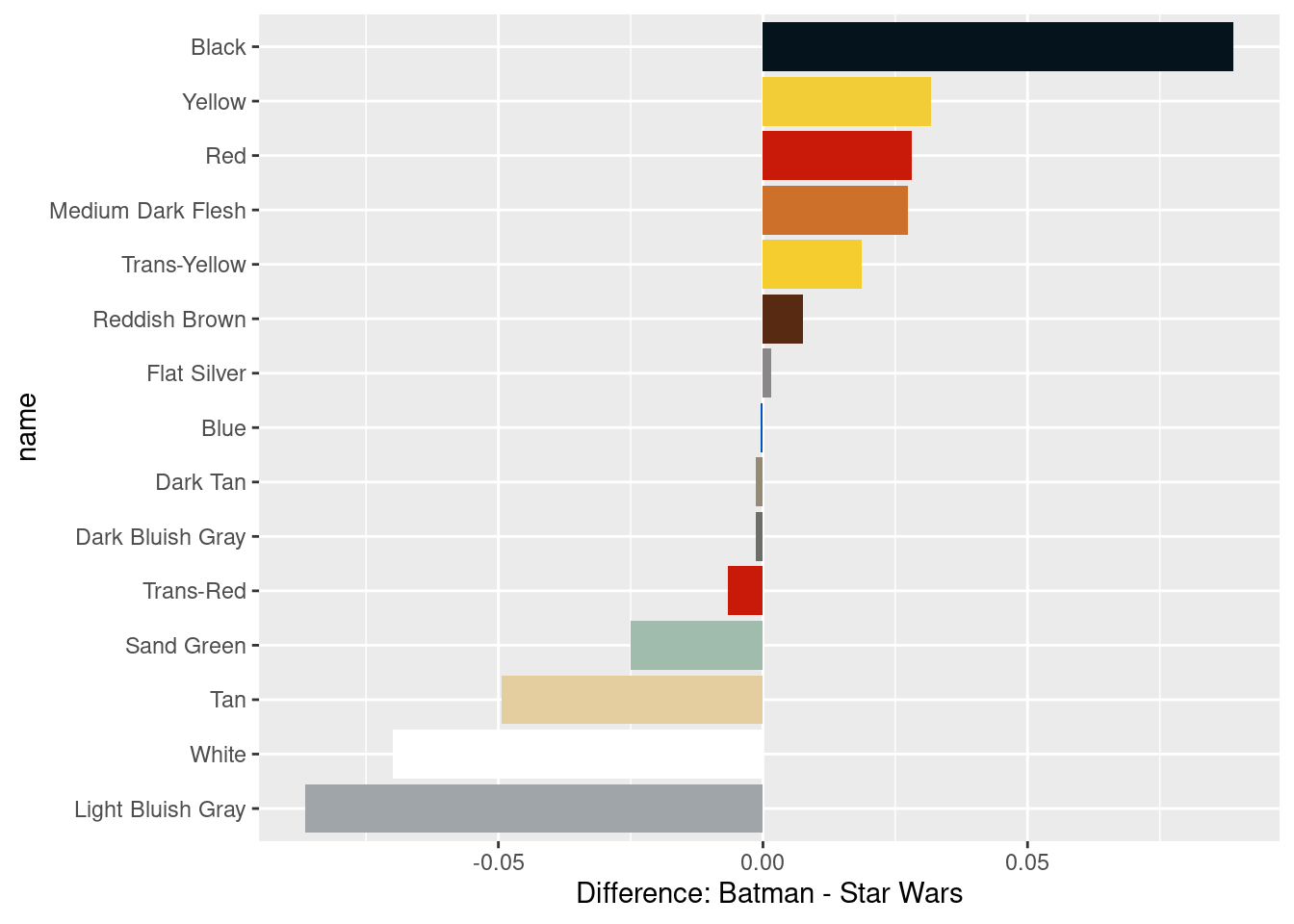
6.4 Case Study: Joins on Stack Overflow Data
Three of the Stack Overflow survey datasets are questions, question_tags, and tags:
- questions: an ID and the score, or how many times the question has been upvoted; the data only includes R-based questions
- question_tags: a tag ID for each question and the question’s id
- tags: a tag id and the tag’s name, which can be used to identify the subject of each question, such as ggplot2 or dplyr
In the following code, we’ll be stitching together these datasets and replacing NAs in important fields.
questions_with_tags <- questions %>%
left_join(question_tags, by = c("id" = "question_id")) %>%
left_join(tags, by = c("tag_id" = "id")) %>%
replace_na(list(tag_name = "only-r"))
questions_with_tags %>%
# Group by tag_name
group_by(tag_name) %>%
# Get mean score and num_questions
summarize(score = mean(score),
num_questions = n()) %>%
# Sort num_questions in descending order
arrange(desc(num_questions))## # A tibble: 7,841 × 3
## tag_name score num_questions
## <chr> <dbl> <int>
## 1 only-r 1.26 48541
## 2 ggplot2 2.61 28228
## 3 dataframe 2.31 18874
## 4 shiny 1.45 14219
## 5 dplyr 1.95 14039
## 6 plot 2.24 11315
## 7 data.table 2.97 8809
## 8 matrix 1.66 6205
## 9 loops 0.743 5149
## 10 regex 2 4912
## # … with 7,831 more rows# Using a join, filter for tags that are never on an R question
tags %>%
anti_join(question_tags, by = c("id" = "tag_id"))## # A tibble: 40,459 × 2
## id tag_name
## <dbl> <chr>
## 1 124399 laravel-dusk
## 2 124402 spring-cloud-vault-config
## 3 124404 spring-vault
## 4 124405 apache-bahir
## 5 124407 astc
## 6 124408 simulacrum
## 7 124410 angulartics2
## 8 124411 django-rest-viewsets
## 9 124414 react-native-lightbox
## 10 124417 java-module
## # … with 40,449 more rowsWe can use the following code to identify how long it takes different questions to get answers.
questions %>%
# Inner join questions and answers with proper suffixes
inner_join(answers, by = c("id" = "question_id"), suffix = c("_question", "_answer")) %>%
# Subtract creation_date_question from creation_date_answer to create gap
mutate(gap = as.integer(creation_date_answer - creation_date_question)) ## # A tibble: 380,643 × 7
## id creation_date_question score_ques…¹ id_an…² creation…³ score…⁴ gap
## <int> <date> <int> <int> <date> <int> <int>
## 1 22557677 2014-03-21 1 2.26e7 2014-03-21 2 0
## 2 22557707 2014-03-21 2 2.26e7 2014-03-21 1 0
## 3 22557707 2014-03-21 2 2.26e7 2014-03-21 4 0
## 4 22558084 2014-03-21 2 2.26e7 2014-03-21 0 0
## 5 22558084 2014-03-21 2 2.26e7 2014-03-24 1 3
## 6 22558084 2014-03-21 2 2.26e7 2014-03-24 5 3
## 7 22558084 2014-03-21 2 3.44e7 2015-12-19 0 638
## 8 22558395 2014-03-21 2 2.26e7 2014-03-21 1 0
## 9 22558395 2014-03-21 2 2.26e7 2014-03-21 2 0
## 10 22558395 2014-03-21 2 2.26e7 2014-03-21 2 0
## # … with 380,633 more rows, and abbreviated variable names ¹score_question,
## # ²id_answer, ³creation_date_answer, ⁴score_answerWe can use the following code to see which questions have the most answers, and which questions have no answers.
# Count and sort the question id column in the answers table
answer_counts <- answers %>%
count(question_id, sort = TRUE)
# Combine the answer_counts and questions tables
questions %>%
left_join(answer_counts, by = c("id" = "question_id")) %>%
# Replace the NAs in the n column
replace_na(list(n = 0))## # A tibble: 294,735 × 4
## id creation_date score n
## <int> <date> <int> <int>
## 1 22557677 2014-03-21 1 1
## 2 22557707 2014-03-21 2 2
## 3 22558084 2014-03-21 2 4
## 4 22558395 2014-03-21 2 3
## 5 22558613 2014-03-21 0 1
## 6 22558677 2014-03-21 2 2
## 7 22558887 2014-03-21 8 1
## 8 22559180 2014-03-21 1 1
## 9 22559312 2014-03-21 0 1
## 10 22559322 2014-03-21 2 5
## # … with 294,725 more rowsanswer_counts <- answers %>%
count(question_id, sort = TRUE)
question_answer_counts <- questions %>%
left_join(answer_counts, by = c("id" = "question_id")) %>%
replace_na(list(n = 0))
tagged_answers <- question_answer_counts %>%
# Join the question_tags tables
inner_join(question_tags, by = c("id" = "question_id")) %>%
# Join the tags table
inner_join(tags, by = c("tag_id" = "id"))
tagged_answers## # A tibble: 497,153 × 6
## id creation_date score n tag_id tag_name
## <int> <date> <int> <int> <dbl> <chr>
## 1 22557677 2014-03-21 1 1 18 regex
## 2 22557677 2014-03-21 1 1 139 string
## 3 22557677 2014-03-21 1 1 16088 time-complexity
## 4 22557677 2014-03-21 1 1 1672 backreference
## 5 22558084 2014-03-21 2 4 6419 time-series
## 6 22558084 2014-03-21 2 4 92764 panel-data
## 7 22558395 2014-03-21 2 3 5569 function
## 8 22558395 2014-03-21 2 3 134 sorting
## 9 22558395 2014-03-21 2 3 9412 vectorization
## 10 22558395 2014-03-21 2 3 18621 operator-precedence
## # … with 497,143 more rowsYou can use this table to determine, on average, how many answers each questions gets.
The following code shows how many answers each question gets on average.
tagged_answers %>%
# Aggregate by tag_name
group_by(tag_name) %>%
# Summarize questions and average_answers
summarize(questions = n(),
average_answers = mean(n)) %>%
# Sort the questions in descending order
arrange(desc(questions))## # A tibble: 7,840 × 3
## tag_name questions average_answers
## <chr> <int> <dbl>
## 1 ggplot2 28228 1.15
## 2 dataframe 18874 1.67
## 3 shiny 14219 0.921
## 4 dplyr 14039 1.55
## 5 plot 11315 1.23
## 6 data.table 8809 1.47
## 7 matrix 6205 1.45
## 8 loops 5149 1.39
## 9 regex 4912 1.91
## 10 function 4892 1.30
## # … with 7,830 more rows# Inner join the question_tags and tags tables with the questions table
questions %>%
inner_join(question_tags, by = c("id" = "question_id")) %>%
inner_join(tags, by = c("tag_id" = "id"))## # A tibble: 497,153 × 5
## id creation_date score tag_id tag_name
## <int> <date> <int> <dbl> <chr>
## 1 22557677 2014-03-21 1 18 regex
## 2 22557677 2014-03-21 1 139 string
## 3 22557677 2014-03-21 1 16088 time-complexity
## 4 22557677 2014-03-21 1 1672 backreference
## 5 22558084 2014-03-21 2 6419 time-series
## 6 22558084 2014-03-21 2 92764 panel-data
## 7 22558395 2014-03-21 2 5569 function
## 8 22558395 2014-03-21 2 134 sorting
## 9 22558395 2014-03-21 2 9412 vectorization
## 10 22558395 2014-03-21 2 18621 operator-precedence
## # … with 497,143 more rows# Inner join the question_tags and tags tables with the answers table
answers %>%
inner_join(question_tags, by = "question_id") %>%
inner_join(tags, by = c("tag_id" = "id"))## # A tibble: 625,845 × 6
## id creation_date question_id score tag_id tag_name
## <int> <date> <int> <int> <dbl> <chr>
## 1 39143935 2016-08-25 39142481 0 4240 average
## 2 39143935 2016-08-25 39142481 0 5571 summary
## 3 39144014 2016-08-25 39024390 0 85748 shiny
## 4 39144014 2016-08-25 39024390 0 83308 r-markdown
## 5 39144014 2016-08-25 39024390 0 116736 htmlwidgets
## 6 39144252 2016-08-25 39096741 6 67746 rstudio
## 7 39144375 2016-08-25 39143885 5 105113 data.table
## 8 39144430 2016-08-25 39144077 0 276 variables
## 9 39144625 2016-08-25 39142728 1 46457 dataframe
## 10 39144625 2016-08-25 39142728 1 9047 subset
## # … with 625,835 more rowsquestions_with_tags <- questions %>%
inner_join(question_tags, by = c("id" = "question_id")) %>%
inner_join(tags, by = c("tag_id" = "id"))
answers_with_tags <- answers %>%
inner_join(question_tags, by = "question_id") %>%
inner_join(tags, by = c("tag_id" = "id"))
# Combine the two tables into posts_with_tags
posts_with_tags <- bind_rows(questions_with_tags %>% mutate(type = "question"),
answers_with_tags %>% mutate(type = "answer"))
# Add a year column, then count by type, year, and tag_name
posts_with_tags %>%
mutate(year = year(creation_date)) %>%
count(type, year, tag_name)## # A tibble: 58,299 × 4
## type year tag_name n
## <chr> <dbl> <chr> <int>
## 1 answer 2008 bayesian 1
## 2 answer 2008 dataframe 3
## 3 answer 2008 dirichlet 1
## 4 answer 2008 eof 1
## 5 answer 2008 file 1
## 6 answer 2008 file-io 1
## 7 answer 2008 function 7
## 8 answer 2008 global-variables 7
## 9 answer 2008 math 2
## 10 answer 2008 mathematical-optimization 1
## # … with 58,289 more rowsby_type_year_tag <- posts_with_tags %>%
mutate(year = year(creation_date)) %>%
count(type, year, tag_name)
# Filter for the dplyr and ggplot2 tag names
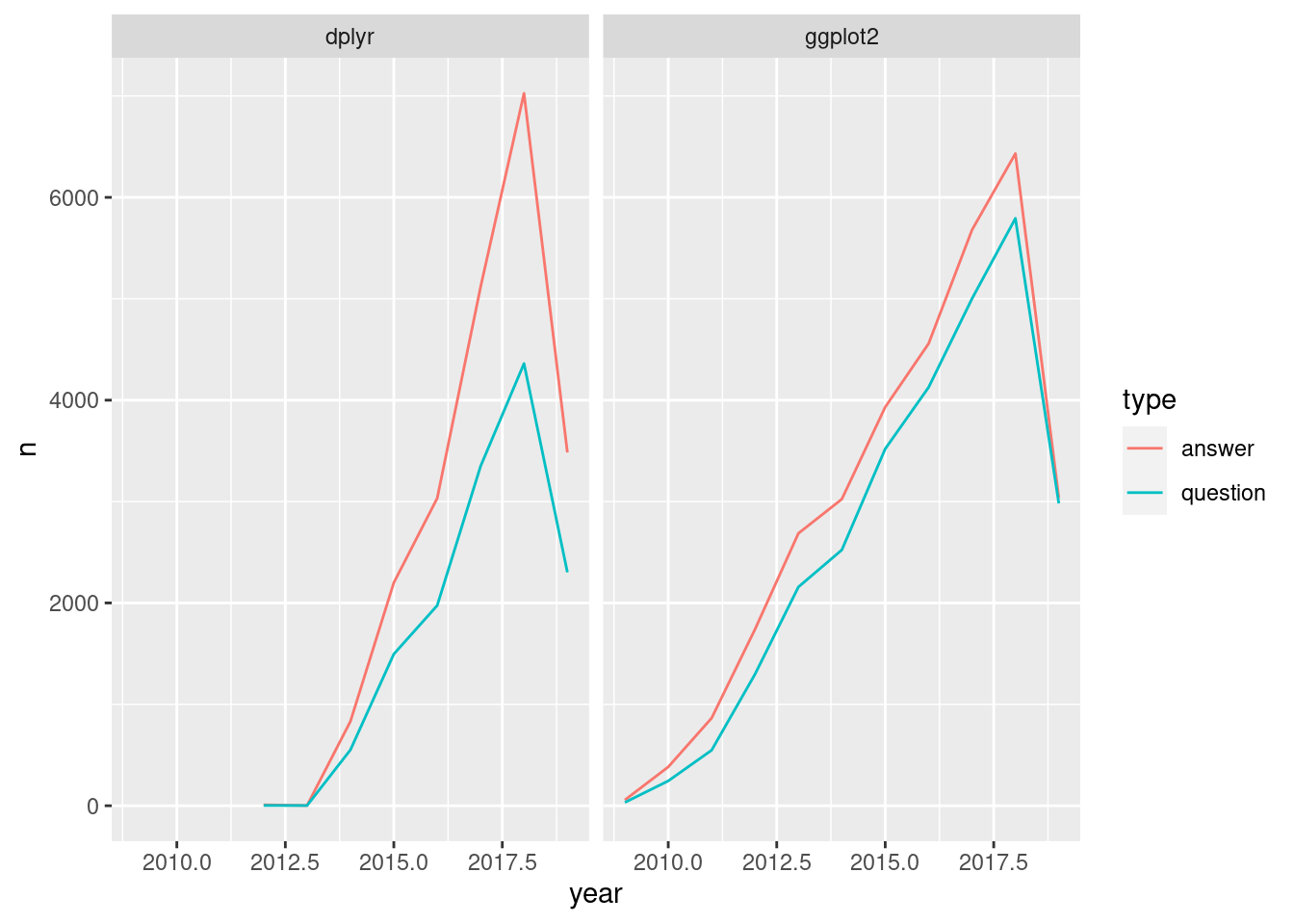
by_type_year_tag_filtered <- by_type_year_tag %>%
filter(tag_name %in% c("dplyr", "ggplot2"))
# Create a line plot faceted by the tag name
ggplot(by_type_year_tag_filtered, aes(year, n, color = type)) +
geom_line() +
facet_wrap(~ tag_name)